一、论文相关信息
1.论文题目
Faster R-CNN
2.论文时间
2015年
3.论文文献
4.论文源码
暂无
二、论文背景及简介
在最早RCNN工作时,限制其运行速度的关键在于其将使用selective search生成的ROI,全部送入卷及网络进行卷积,速度很慢。Fast RCNN对其进行了优化,使用CNN提取feature map,并获得由selective search生成的ROI在feature map上的映射,将feature送入之后的卷基层进行处理,这极大地缩短了运行时间。而Faster RCNN从ROI生成的方法来进行优化,使用RPN来替换selective search,来生成ROI,这从另一个角度降低了运行时间。
论文表示,Faster RCNN 在test阶段,198ms 一张图片;Fast RCNN 320ms 一张图片
三、知识储备
1、anchor
anchor实际上就是一个在原始图片空间的Region Proposal,其有大小(宽×高)、有宽高比(aspect rations),作者使用anchor这个词来代指feature map上可能对应的这样的一个Region Proposal。作者对每一块区域(3×3,即RPN的滑动窗口大小),假定存在9个anchor(大小分别为128、256、512,宽高比为1:1、1:2、2:1,这样3*3中anchor)。
2、RPN(Region Proposal Networks)
RPN是一个用于生成候选框的网络,使用RPN代替Fast RCNN的Selective Search(SS),即Faster RCNN。RPN其创新点在于其在feature map上选择候选框,与网络其他部分共享参数,加快了网络。
Faster RCNN网络图如下:

RPN网络图如下:

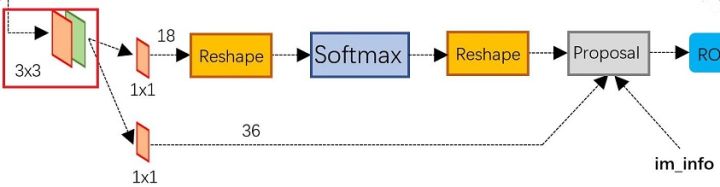
在得到feature map(假定为13 13 256 )后,经过一个3 3的卷积网络(使每一个中心点获得周围点的receptive field),对得到的新的feature map(13 13 256),假定每一个中心点存在k(论文中使用了k=9)个anchor,对13 13上的每一个点将会有256d的维度,将每一个点的256d的这个vector经过两个1 1卷积层(`1 1 2k,1 1 4k`),一个用于分类(是否为物体2 k),一个用于得到anchor内具体的region proposal (即4 * k,只有在分类中是物体时才会进行这个预测)
完整的RPN网络如下:
四、test阶段

假设该模型为N分类结果,一些细节将会在下文进行介绍
- 输入一张图片
- 特征提取:将整张图片放入卷积网络,得到feature map
- 候选框提取,将feature map输入RPN得到,得到候选框,从候选框中使用NMS,并选取前300(超参数)个候选框作为ROI。
- ROI Pooling:根据feature map 已经从RPN得到的以ROI 来进行ROI Pooling 得到固定大小的特征向量
- 分类与回归:将得到的特征向量放入fc层,将得到的feature,分别放入bbox回归分类器以及softmax分数分类器,对bbox的位置信息进行修正,并得到分类信息。
五、train阶段
根据test阶段,我们可以知道Faster RCNN主要有两个训练任务,为:
1、对Fast RCNN的训练
2、对RPN的训练
Faster RCNN是一个two-stage即分两步的训练模式,且对RPN网络的训练以及Fast RCNN网络的训练有独特的顺序。
下文将会对其细节进行讲解
1、对Fast RCNN的训练
与Fast RCNN网络的训练方法大致相似。
2、对RPN的训练
在训练过程中:
对分类网络的训练,设定anchor与ground-truth的IOU大于0.7的设为正例,小于0.3的设为反例。同时,作者说明那些既不是正例,也不是反例的anchor对网络的训练没有影响。
对回归网络的训练,与Fast RCNN对回归网络的训练相似。
同时作者将两个训练的Loss联合起来。
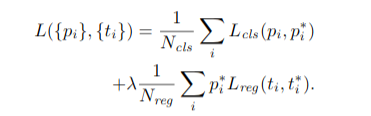
同时作者发现,参数 lambda 对网络的影响不大。
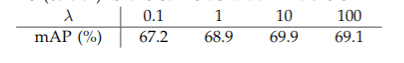
训练过程中,每一个mini batch中,作者在一整张图片中随机的选取了256个anchors(正例与反例比值1:1),进行训练。
3、整个网络的联合训练
作者在论文中提到,对整个网络的联合训练有三种方式,Alternating traing、Approximate joint training、Non-approximate joint training。
作者采用了第一种训练方法(其他过程可查阅论文),分为四步
1、首先训练一次RPN,方法如第二点中所示,且feature map提取网络采用ImageNet-pre-trained的model
2、然后使用有第一步生成的proposal,去训练Fast RCNN,且feature map提取网络也采用ImageNet-pre-trained的model,这两个与训练的网络步是同一个,即暂时不共享网络参数。
3、使用Fast RCNN的提取feature map的model,微调RPN的网络层。此时,两个网络开始共享参数了。
4、保持model不变,使用生成的proposal微调Fast RCNN
这个过程不断迭代,来不断对网络进行优化。
六、实验结果
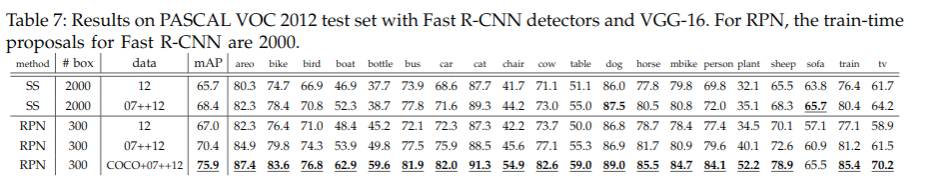
Faster RCNN 在test阶段,198ms 一张图片;Fast RCNN 320ms 一张图片,加快了网络速度.
七、论文细节与思考
1、Translation-Invariant Anchors(平移不变性)
Translation-Invariant Anchors 是指当一个物体发生翻转、平移、缩放时,检测网络依旧能很好的检测出来。由于网络中各种各样的anchor以及与anchor相关的回归网络是的Faster RCNN具备Translation-Invariant。
2、anchor的尺寸选择
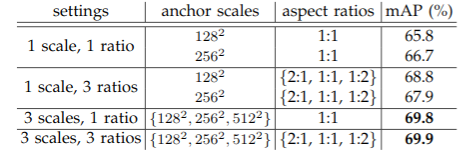
作者在论文中提到,使用3种scale或者3种aspect rations会使网络具有很好的效果,不过同时使用3种scale和3种aspect rations对网络提升不大,不过作者为了提高网络的灵活程度,同时使用了3种scale和3种aspect rations。
3、ROI数量是否越多越好
作者通过比较发现,RPN网络对ROI的数量并不敏感,相反,SS(Selective search)对其比较敏感。这说明NMS并不会损失mAP,并且可能会减少错误。同时作者发现当更改ROI的数量时,其recall基本保持不变,而SS等其他方法变化较大,这解释了为什么ROI数量只有300依旧可以达到很好的效果


4、one-stage?two-stage?multi-stage?
此处引用他人博客
目标检测的流程如下:
multi-stage步骤
two-stage步骤




one-stage步骤



%E4%B9%8B%20R-CNN/cover.png?raw=true)
%E4%B9%8BFast%20R-CNN/cover.jpg?raw=true)
%E4%B9%8BYOLOv1/cover.png?raw=true)
%E4%B9%8BMask-RCNN/cover.png?raw=true)
%E4%B9%8BYOLO%20v2/cover.png?raw=true)